Cline: Bring Your Own AI
Keeping playing with local models and surrounding services, I replaced the original Ollama service with its lean and fast relative - Llama.cpp. The transition didn't sit well with the VS Code Cline plugin, so I had to conduct some research and make a few changes.


Keeping playing with local models and surrounding services, I replaced the original Ollama service with its lean and fast relative - Llama.cpp. The transition didn't sit well with the VS Code Cline plugin, so I had to conduct some research and make a few changes.
Although Ollama and Llama.cpp are close relatives, the disparity API is significant enough to break the Cline functionality. Short research yielded two alternatives: an OpenAI-compatible API and an Anthropic-compatible API.
I have decided to start with the Anthropic option, but quickly gave up. Anthropic provider for Cline allows you to specify a custom model endpoint, but model names are pre-coded, and you can only choose one from the dropdown. Reasonably enough, my server container declines messages with an unknown model name.
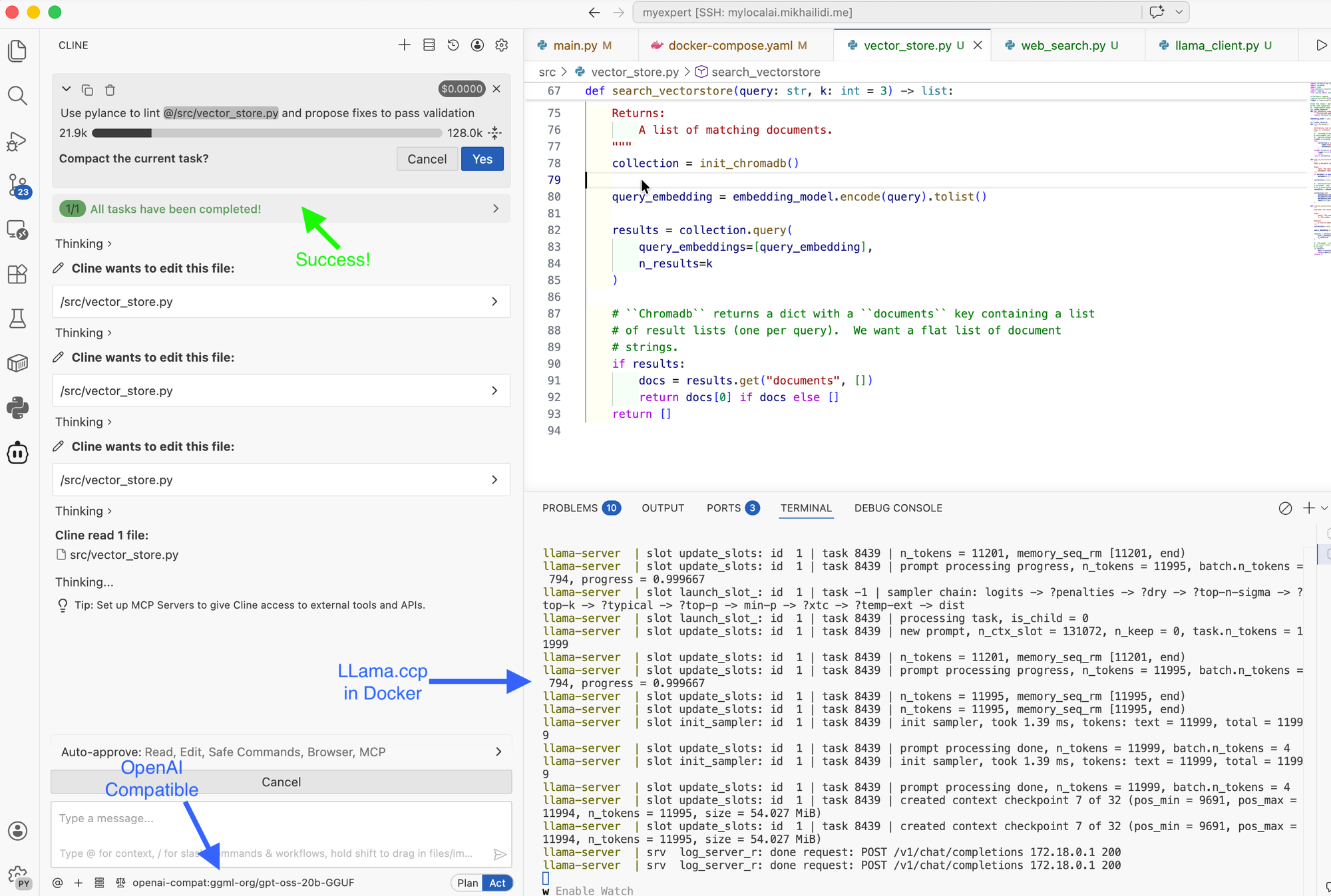
Next try was for the "OpenAI Compatible" provider. This provider is fully customizable and can either retrieve the list of models registered on the server or allow you to specify any other model name.
Since I started the server with the GPT OSS argument --gpt-oss-20b-default, the model name for the Cline configuration is gpt-oss-20b. Another difference from Ollama, the OpenAI-compatible provider requires the API key. Use one if you define it through the server configuration, or put any value if your server is not protected.
Save the provider configuration, and select your new model for plans and acts.
There are no new takeaways or revelations:
- Local models, as good as your acceleration hardware. On the RTX3060, the 12 GB of video RAM drastically limits the size of models you can run and response speed.
- The same limits force the usage of smaller context windows, which makes your agent a little bit dimmer than its youngest relatives.
- Although the modern models do not demonstrate record speeds, the local model is more like a human; some answers take minutes to process and complete. Be patient.
- You may experiment with agents and skills, but you may want to keep your configuration files very lean.
With all that said, I keep my local agent for simple executions that do not require complex autonomy or deep reasoning and planning. Especially if you know the limitations and can deal with them.