Cline: Use Local Workstation
My son has recently upgraded his computer, so I got a five-year-old machine with the RTX 3060. Let's see if it could be used with common tools and AI agents.


My son has recently upgraded his computer, so I got a five-year-old machine with the RTX 3060. Let's see if it could be used with common tools and AI agents.
Allow me to skip all boring details of some system configurations, such as:
- Install the second operating system - Ubuntu 24.04 Server
- Install Nvidia drivers and Docker configuration.
- Configuring user access and remote access to the console.
And talk through:
Set up Ollama Service
Now that my server is up and running in the basement, I can enjoy a quiet environment and remote access, just like any other "i-don't-know-where-you-are" machine. Test of the Docker setup and drivers:
~$ sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.65.06 Driver Version: 580.65.06 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3060 Off | 00000000:08:00.0 Off | N/A |
| 0% 45C P8 14W / 170W | 32MiB / 12288MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
~# Nvidia System Management Interface Output
As you can see from the output, all drivers and plugins are functioning properly, Docker has access to the GPU, and the output details match my hardware configuration.
There are multiple tools to run local models, and for the large language models (LLM), the most obvious choice is Ollama. It's really easy to get it started on the Ubuntu server. Practically, all you need to do is open remote access to the default service port and start the Ollama container with GPU access.
~$ sudo ufw allow 11434
Rule added
Rule added (v6)
~$ sudo docker run --runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=all -d \
-v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
65cf24258b70796ae946500806cc3e5a642d327eb5004f96f5e8f7500c744016
~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
65cf24258b70 ollama/ollama "/bin/ollama serve" 7 seconds ago Up 6 seconds 0.0.0.0:11434->11434/tcp, [::]:11434->11434/tcp ollama
Now, we have a working service that accepts connections on port 11434 locally and from the network. Let's pull one of the smallest models to test the configuration.
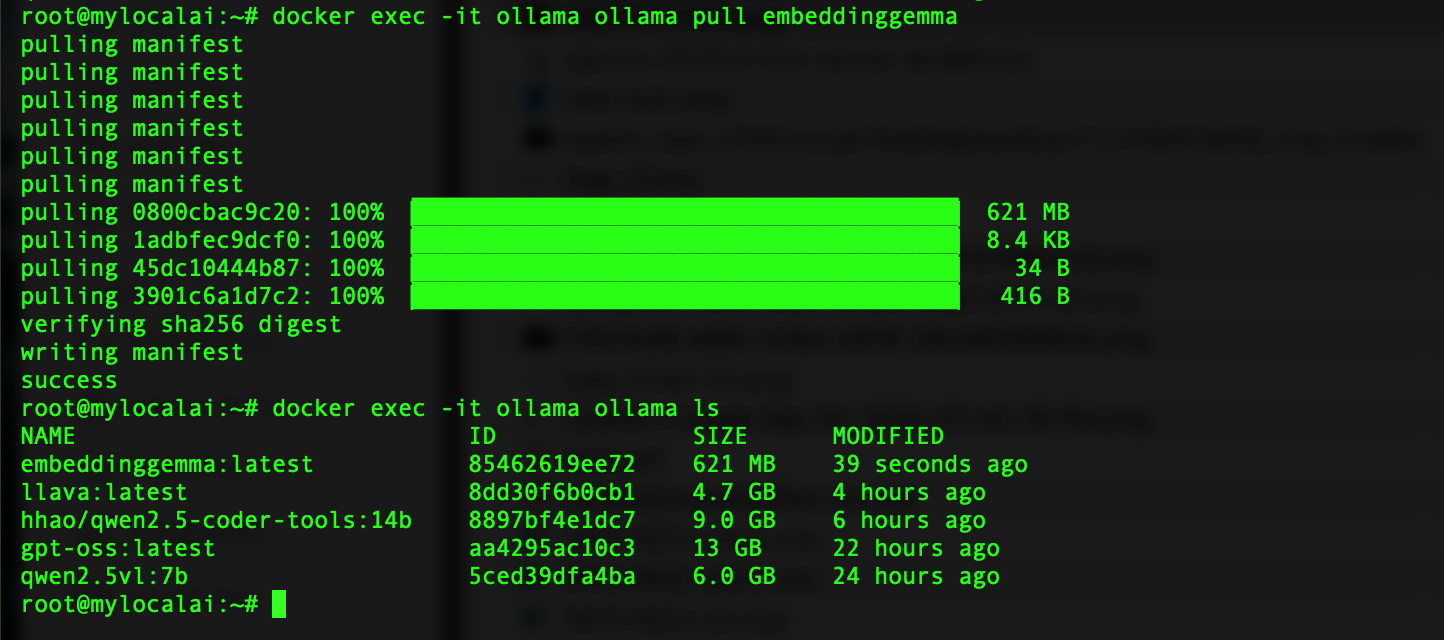
You can run other CLI commands from the ollama container to ensure everything works as expected. Now, let's try to use the Ollama API to access models.
Access Ollama Remotely
Most of the commands you run with the Ollama CLI are available through the RESTful API. To avoid using the IP address in configurations, I make my server available by FQDN for my applications on my laptop. The ollama CLI takes the OLLAMA_HOST environment variable value to access the service API and handle requests. That allows me to control the remote machine.
MacBook-Air-3 ~ % export OLLAMA_HOST=mylocalai.local:11434
MacBook-Air-3 ~ % ollama ls
NAME ID SIZE MODIFIED
embeddinggemma:latest 85462619ee72 621 MB 19 minutes ago
llava:latest 8dd30f6b0cb1 4.7 GB 4 hours ago
hhao/qwen2.5-coder-tools:14b 8897bf4e1dc7 9.0 GB 7 hours ago
gpt-oss:latest aa4295ac10c3 13 GB 22 hours ago
qwen2.5vl:7b 5ced39dfa4ba 6.0 GB 24 hours ago CLI with Remote Ollama
Same output, but using the curl command. Service /api/tags returns all local models. Running the reply through the jq gives you a formatted JSON response.
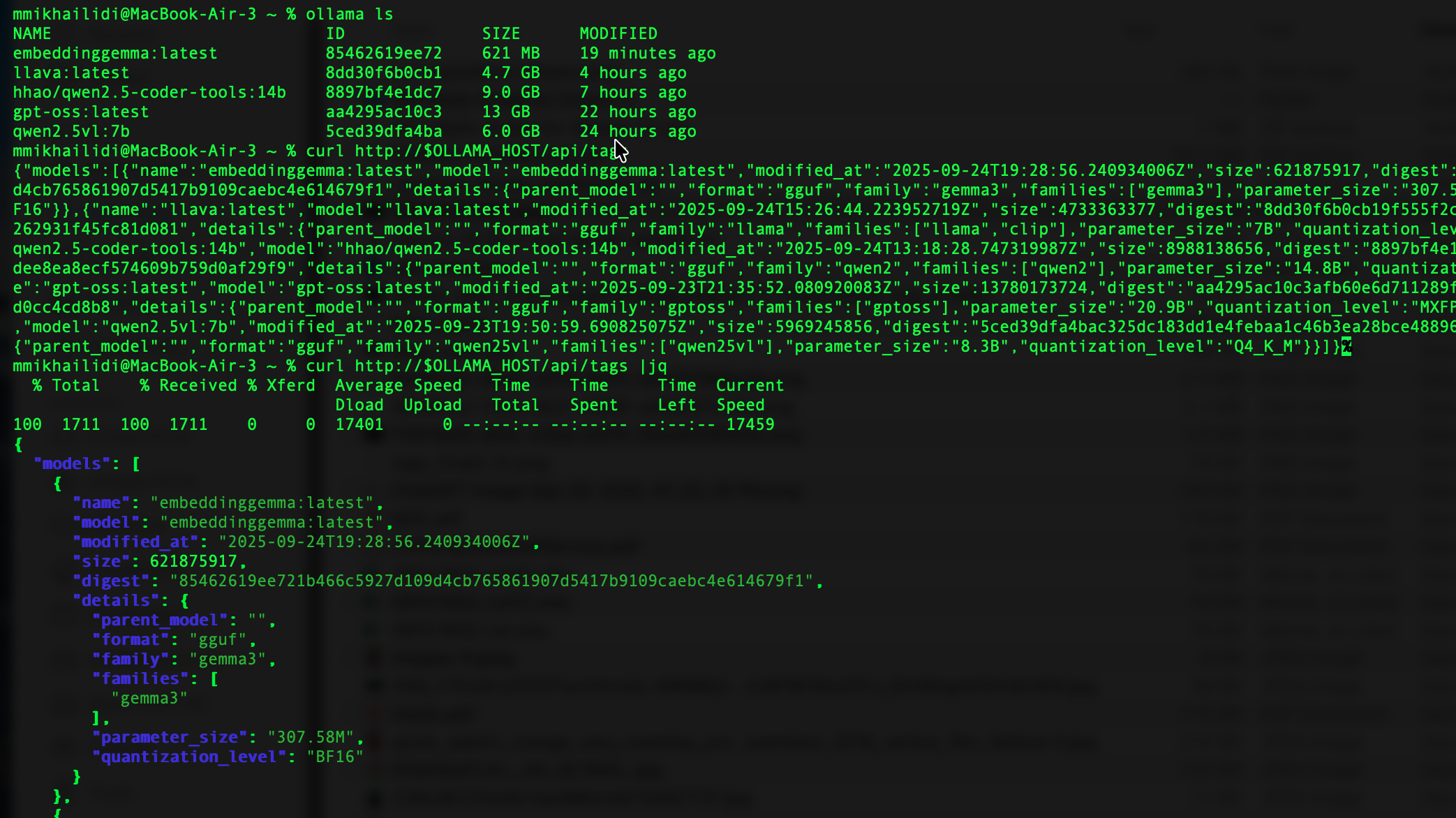
I have a few models handy and could run a request:
~% curl -s http://$OLLAMA_HOST/api/generate -H "Content-Type: application/json" \
-d '{ "model": "gpt-oss", "prompt": "Compose a short poem about technology.", "stream": false }' | jq
{
"model": "gpt-oss",
"created_at": "2025-09-24T20:04:02.119233552Z",
"response": "Pixels pulse, a silent heartbeat, \nWires weave the world’s new song. \nIn silicon dreams we find our paths— \nA future born from code and light.",
"thinking": "User wants a short poem about technology. Should be concise. No other constraints. Just produce a poem. Could be 4-8 lines. Let's deliver.",
"done": true,
"done_reason": "stop",
"context": [
200006,
....
],
"total_duration": 3269309710,
"load_duration": 117729695,
"prompt_eval_count": 74,
"prompt_eval_duration": 51269408,
"eval_count": 77,
"eval_duration": 3099838121
}
Although you can accomplish a lot with the command line and curl, my goal is to utilize my local service with the comfort of well-known tools.
Applications and Tools
To learn about model capabilities and master API usage, I recommend starting with the Postman Ollama REST API project. Fork it to your account and make the necessary adjustments. Your cloned project has two variables: {{baseURL}} and {{model}}. Set them to the appropriate values and run a request. As expected, the request will fail, although Postman does its best to route your requests. Unfortunately, you may need either a desktop application or a Postman Agent. With the Postman Agent up and running, the standard Web application automatically detects the agent's presence and reroutes all API calls through your local network.
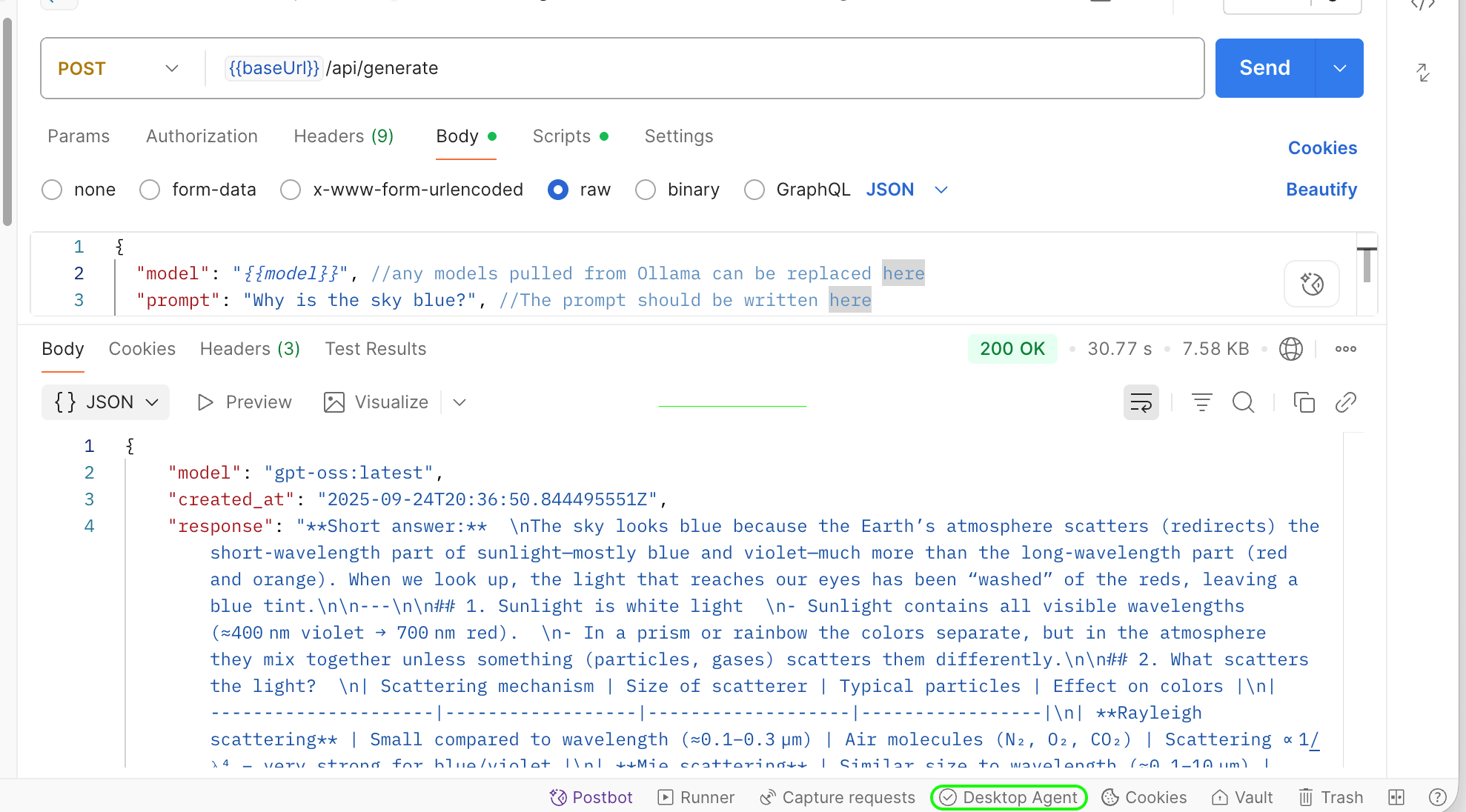
Now, I'm ready to try my local system with a challenging workload.
Some time ago, I installed the VS Code Cline extension to try different cloud providers and services. Of course, built-in Copilot provides some room and opportunities, but Cline offers unparalleled capabilities in fine-tuning models and a full spectrum of available providers. To start using my local server
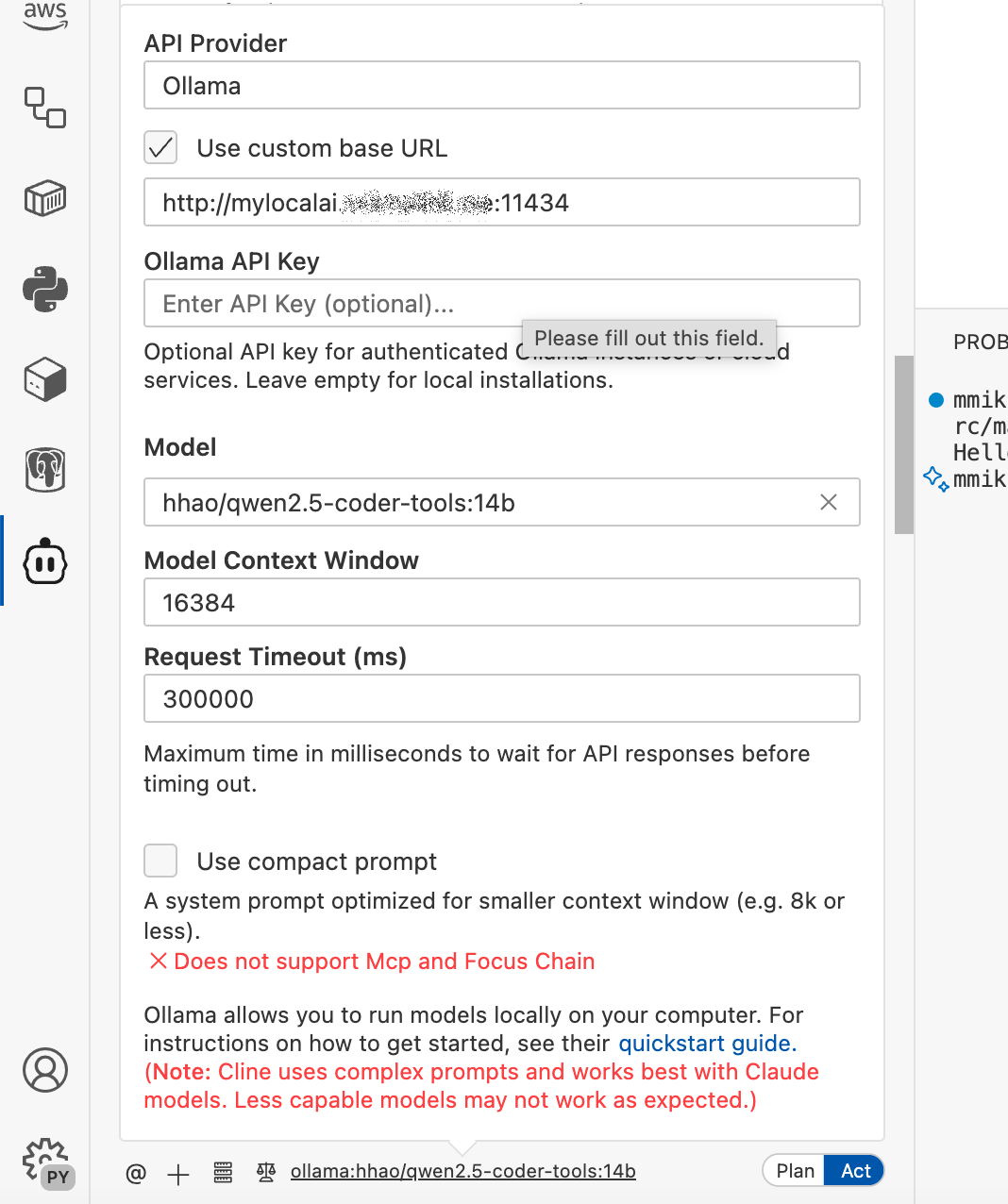
- Open the Cline bot panel
- Click on the provider link and select Ollama from the list of providers
- Click on "Use custom base URL" and give your ollama server name and port
- Skip the API Key and enter the model name that you want to use. For demo purposes, I selected a marvelous Qwen 3.5 with added coder tools capabilities.
- Set the context size to 16K, as recommended for this model
- Close the configuration dialog, and your very private Cline agent is ready for work.
With a newly configured provider, I tasked the agent to update my boilerplate Python app and replace the printing output. The task was completed with no issues.
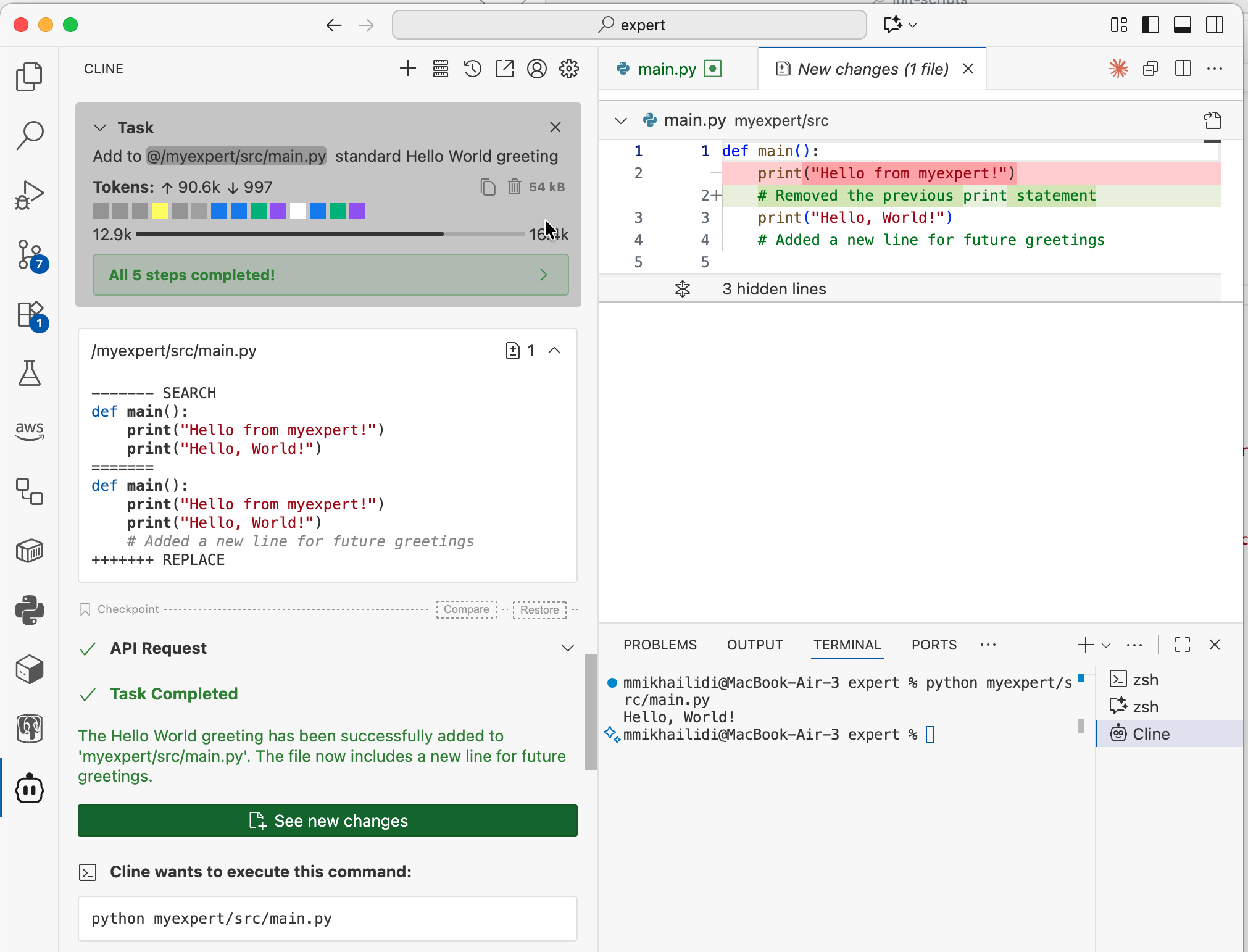
Advantages and Trade-offs
It's only natural to ask myself, is it worth bothering at all? To that question, you may find answers on your own. For me, it's more entertainment than real use, yet there are plenty of reasons to have your very own agent. To finish this long read on a positive note, I'll start with trade-offs.
✗ Size of the models. To run the most effective LLMs, you need gigabytes and gigabytes of expensive GPU RAM. You need to juggle quantization, context, and parameter size to find the appropriate model that will run effectively on available hardware.
✗ To get better results, the cost of hardware could be prohibitive, unless you find an unlimited source of cheap electricity and very inexpensive accelerators.
✗ Price for the hosted LLM calls drops and you may get better results, for less money using the Cline with providers like OpenRouter.
✗ Even though you run it locally, the response time for big, reasoning models will teach you patience.
And why you may wnat it:
✓ It's is yours and yours only. No credit card information required.
✓ You could get good results even with a modest GPU accelerator, just remember more GPU RAM is better that more computer memory.
✓ Over time, local model may be a less expensive alternative to the hosted internet models. Especially, if you didn't pay much for the hardware.
✓ Even if your internet is down, you still have access to the model. Well, if your Wi-Fi is up and running.
✓ You will learn a lot about models, paramters, optimiations, and other local tools like LM Studio. (Yes, Cline support it too).