When specialty beats functionality
While back I wrote a short piece about Pandoc. My excitement about it stands true, yet it's a last-century utility you don't want or can't use in cloud-native applications. Well, I found a new one - WKHTMLTOx


While back I wrote a short piece about Pandoc. My excitement about it stands true, yet it's a last-century utility you don't want or can't use in cloud-native applications. Well, I found a new one - WKHTMLTOx
While the name of the utility as much unpronounceable as my last name it light, versatile, and self-content. Developers offer you two compiled and statically liked options: wkhtmltopdf and wkhtmltoimg. The utility uses QT WebKit to render PDFs or images from various sources. It does not require any dependencies, packages, or graphic engines. All it does is convert virtually anything to PDF or imageThehe site is lean, laconic as the product itself, and mostly reproduces the application's manual page. What stands it out - transformation quality and low resource usage. For example, it takes less than 5 minutes to convert a 25 Mb HTML document to a 93Mb PDF, and what is even more impressive - using only 2Gb of RAM.
Deveopers offer releases for the most common platforms and what important to me there is a prebuuld AWS Lambda Layer for AWS Linux2. Now, there is only one component missing - JavaScript wrapper for the utility. Of course you can do it yourself and Idid, but it worth to search and see if someone more gifted has done it already. sure enough I found a quite versatile and reliable implementation with no brainer name wkhtmltopdf. Many thanks to collaborators, they have added support for NodeJS Streams. This approach perfectly fits AWS S3 API and allows you to convert s3 objects on the fly.
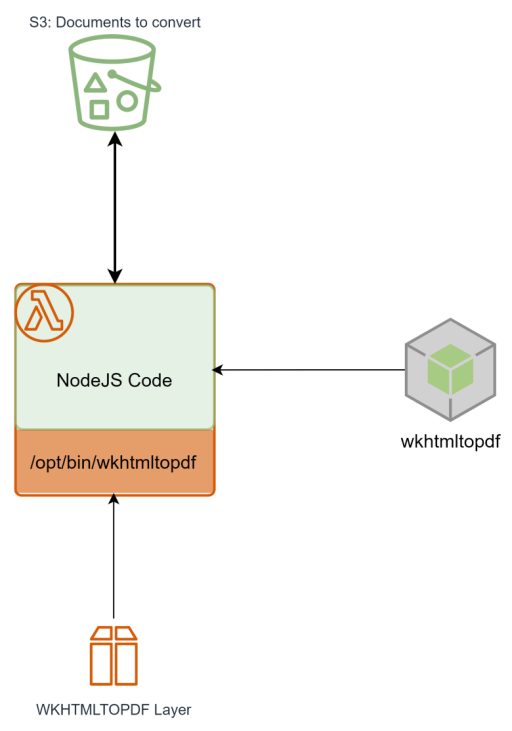
My overall solution looks like the diagram below. Lambda code imports a wkhtmltopdf module and runs on top of wkhtmltopdf lambda layer. Lambda could receive events from application or from S3 itself. just a few tips to consider:
- Point NodeJS object to the utility from the layer. It resides in /opt/bin. Alternatively, you could update process.ev.PATH value
- To not be disappointed with conversion quality, don't forget about another environment variable - FONTSCONFIG_FILE. I just added it to the Lambda configuration FONTSCONFIG_FILE=/opt/fonts/fonts.conf.
- Converter is smart enough to pull images along, as long as they are available. it's not a big deal if the image reference is an absolute URL, but for images with the relative path you may want to have a local copies before conversion happens.
- Speaking of streams, wkhtmltopdf will search images in the /tmp folder. So, if your source document refers to image as <img src='images/my-picture.png'/> the image file should be available /tmp/images/my-picture.png first.